1、简单爬虫源码:
最近在家没事做,打算玩玩爬虫,作为爬虫的新手,这也算是helloworld程序了!因为需求简单,所以只用requests库和Beautiful Soup库,没有用到复杂的爬虫框架,下一步可以进一步学习一下Scrapy框架。
import requests #导入requests包
from bs4 import BeautifulSoup
def detail_url(url):#根据传入的url获取url页面的数据
strhtml = requests.get(url)#Get方式获取网页数据
soup = BeautifulSoup(strhtml.text, 'lxml')
user_name=soup.select('body > div.posr.player-head-wrap.mt-nav.player-head-season.player-head-id0 > div > h1 > span.vam.ellip.name')[0].text
user_elo=soup.select('body > div.player-main-wrap > div > ul > li.posr > span')[0].text
user_rating=soup.select('body > div.player-main-wrap > div > ul > li:nth-child(4) > span')[0].text
print(user_name+"天梯分:"+user_elo+" Rting:"+user_rating)
def crawl():#从战队页面获取每个队员的url
url='https://www.5ewin.com/team/tf'
strhtml=requests.get(url)#Get方式获取网页数据
soup=BeautifulSoup(strhtml.text,'lxml')
users = soup.select('body > div.team-main-wrap > div > div.team-detail-main > div.member > ul > li')
num=len(users)
print("本战队共有",num,"人")
for user in users:
url=user.select('a')[0]['href']
detail_url(url)
crawl()
其中
soup.select()函数中的内容定位可以使用谷歌chrome浏览器查看(如下图)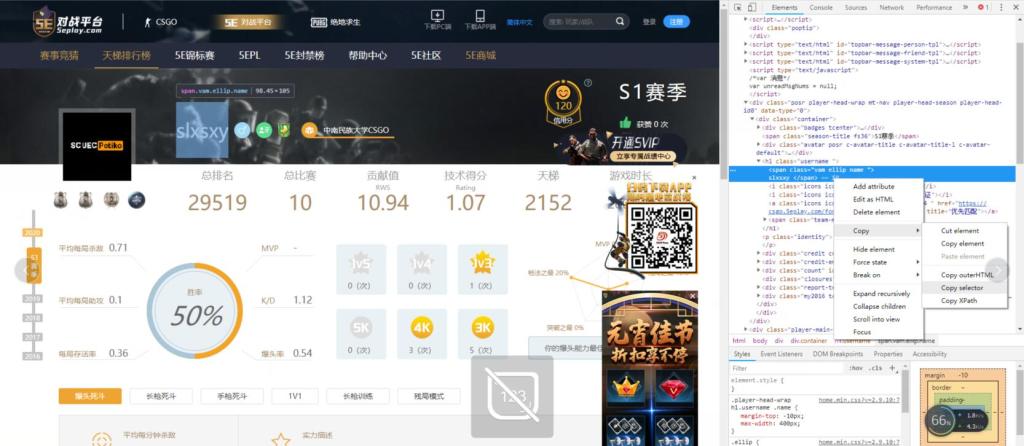
2、简单爬虫模板:
import requests #导入requests包
from bs4 import BeautifulSoup
url='https://www.baidu.com/'
strhtml=requests.get(url)#Get方式获取网页数据
soup=BeautifulSoup(strhtml.text,'lxml')
data = soup.select('body > div.team-main-wrap > div > div.team-detail-main > div.member > ul > li')
print(data)下面附一些学习资料:
1、Python爬虫入门教程:超级简单的Python爬虫教程:http://c.biancheng.net/view/2011.html
2、python实用入门视频教程(百度盘):
链接:https://pan.baidu.com/s/1O46m-p0Rx4GO9KG3FMdNPg
提取码:hdze
