今天接了一个代录网课的单,一共25节课,每节课3小时左右。
如果是只能客户端观看网课的软件那可能就只能用OBS一个个挂机录制了,十分麻烦。观察了一下客户使用的课程软件部分课程支持网页观看网课,部分只能在软件内观看。对于网页能观看的网课想到通过网页解析视频的m3u8地址把视频直接下载下来,对于只能在软件内观看的课程,我选择用抓包的方式获取视频的地址进而下载下来。
首先F12进入开发者模式很快找到了m3u8地址

m3u8是什么?m3u8是苹果公司推出的视频播放标准,是基于HTTP的流媒体网络传输协议(HLS)。HLS是把整个流分成一个个小的基于 HTTP 的文件来下载。m3u8 文件实质是一个播放列表(playlist),其内部文字使用的都是 utf-8 编码。
客户端只需按顺序下载上述片段资源,依次进行播放即可。而对于直播来说,客户端需要定时重新请求该 m3u8 文件,看下是否有新的片段数据需要进行下载并播放。
按照原理参考网上资料使用下面python代码即可实现下载并转成mp4格式
import os
import re
import sys
import queue
import base64
import platform
import requests
import urllib3
from concurrent.futures import ThreadPoolExecutor
class ThreadPoolExecutorWithQueueSizeLimit(ThreadPoolExecutor):
"""
实现多线程有界队列
队列数为线程数的2倍
"""
def __init__(self, max_workers=None, *args, **kwargs):
super().__init__(max_workers, *args, **kwargs)
self._work_queue = queue.Queue(max_workers * 2)
def make_sum():
ts_num = 0
while True:
yield ts_num
ts_num += 1
class M3u8Download:
"""
:param url: 完整的m3u8文件链接 如"https://www.bilibili.com/example/index.m3u8"
:param name: 保存m3u8的文件名 如"index"
:param max_workers: 多线程最大线程数
:param num_retries: 重试次数
:param base64_key: base64编码的字符串
"""
def __init__(self, url, name, max_workers=64, num_retries=5, base64_key=None):
self._url = url
self._name = name
self._max_workers = max_workers
self._num_retries = num_retries
self._file_path = os.path.join(os.getcwd(), self._name)
self._front_url = None
self._ts_url_list = []
self._success_sum = 0
self._ts_sum = 0
self._key = base64.b64decode(base64_key.encode()) if base64_key else None
self._headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
urllib3.disable_warnings()
self.get_m3u8_info(self._url, self._num_retries)
print('Downloading: %s' % self._name, 'Save path: %s' % self._file_path, sep='\n')
with ThreadPoolExecutorWithQueueSizeLimit(self._max_workers) as pool:
for k, ts_url in enumerate(self._ts_url_list):
pool.submit(self.download_ts, ts_url, os.path.join(self._file_path, str(k)), self._num_retries)
if self._success_sum == self._ts_sum:
self.output_mp4()
self.delete_file()
print(f"Download successfully --> {self._name}")
def get_m3u8_info(self, m3u8_url, num_retries):
"""
获取m3u8信息
"""
try:
with requests.get(m3u8_url, timeout=(3, 30), verify=False, headers=self._headers) as res:
self._front_url = res.url.split(res.request.path_url)[0]
if "EXT-X-STREAM-INF" in res.text: # 判定为顶级M3U8文件
for line in res.text.split('\n'):
if "#" in line:
continue
elif line.startswith('http'):
self._url = line
elif line.startswith('/'):
self._url = self._front_url + line
else:
self._url = self._url.rsplit("/", 1)[0] + '/' + line
self.get_m3u8_info(self._url, self._num_retries)
else:
m3u8_text_str = res.text
self.get_ts_url(m3u8_text_str)
except Exception as e:
print(e)
if num_retries > 0:
self.get_m3u8_info(m3u8_url, num_retries - 1)
def get_ts_url(self, m3u8_text_str):
"""
获取每一个ts文件的链接
"""
if not os.path.exists(self._file_path):
os.mkdir(self._file_path)
new_m3u8_str = ''
ts = make_sum()
for line in m3u8_text_str.split('\n'):
if "#" in line:
if "EXT-X-KEY" in line and "URI=" in line:
if os.path.exists(os.path.join(self._file_path, 'key')):
continue
key = self.download_key(line, 5)
if key:
new_m3u8_str += f'{key}\n'
continue
new_m3u8_str += f'{line}\n'
if "EXT-X-ENDLIST" in line:
break
else:
if line.startswith('http'):
self._ts_url_list.append(line)
elif line.startswith('/'):
self._ts_url_list.append(self._front_url + line)
else:
self._ts_url_list.append(self._url.rsplit("/", 1)[0] + '/' + line)
new_m3u8_str += (os.path.join(self._file_path, str(next(ts))) + '\n')
self._ts_sum = next(ts)
with open(self._file_path + '.m3u8', "wb") as f:
if platform.system() == 'Windows':
f.write(new_m3u8_str.encode('gbk'))
else:
f.write(new_m3u8_str.encode('utf-8'))
def download_ts(self, ts_url, name, num_retries):
"""
下载 .ts 文件
"""
ts_url = ts_url.split('\n')[0]
try:
if not os.path.exists(name):
with requests.get(ts_url, stream=True, timeout=(5, 60), verify=False, headers=self._headers) as res:
if res.status_code == 200:
with open(name, "wb") as ts:
for chunk in res.iter_content(chunk_size=1024):
if chunk:
ts.write(chunk)
self._success_sum += 1
sys.stdout.write('\r[%-25s](%d/%d)' % ("*" * (100 * self._success_sum // self._ts_sum // 4),
self._success_sum, self._ts_sum))
sys.stdout.flush()
else:
self.download_ts(ts_url, name, num_retries - 1)
else:
self._success_sum += 1
except Exception:
if os.path.exists(name):
os.remove(name)
if num_retries > 0:
self.download_ts(ts_url, name, num_retries - 1)
def download_key(self, key_line, num_retries):
"""
下载key文件
"""
mid_part = re.search(r"URI=[\'|\"].*?[\'|\"]", key_line).group()
may_key_url = mid_part[5:-1]
if self._key:
with open(os.path.join(self._file_path, 'key'), 'wb') as f:
f.write(self._key)
return f'{key_line.split(mid_part)[0]}URI="./{self._name}/key"'
if may_key_url.startswith('http'):
true_key_url = may_key_url
elif may_key_url.startswith('/'):
true_key_url = self._front_url + may_key_url
else:
true_key_url = self._url.rsplit("/", 1)[0] + '/' + may_key_url
try:
with requests.get(true_key_url, timeout=(5, 30), verify=False, headers=self._headers) as res:
with open(os.path.join(self._file_path, 'key'), 'wb') as f:
f.write(res.content)
return f'{key_line.split(mid_part)[0]}URI="./{self._name}/key"{key_line.split(mid_part)[-1]}'
except Exception as e:
print(e)
if os.path.exists(os.path.join(self._file_path, 'key')):
os.remove(os.path.join(self._file_path, 'key'))
print("加密视频,无法加载key,揭秘失败")
if num_retries > 0:
self.download_key(key_line, num_retries - 1)
def output_mp4(self):
"""
合并.ts文件,输出mp4格式视频,需要ffmpeg
"""
cmd = f"ffmpeg -allowed_extensions ALL -i '{self._file_path}.m3u8' -acodec \
copy -vcodec copy -f mp4 '{self._file_path}.mp4'"
os.system(cmd)
def delete_file(self):
file = os.listdir(self._file_path)
for item in file:
os.remove(os.path.join(self._file_path, item))
os.removedirs(self._file_path)
os.remove(self._file_path + '.m3u8')
if __name__ == "__main__":
url_list = input("输入url,若同时输入多个url时要用空格分开:").split()
name_list = input("输入name,若同时输入多个name要用空格分开:").split()
# 如果M3U8_URL的数量 ≠ SAVE_NAME的数量
# 下载一部电视剧时,只需要输入一个name就可以了
sta = len(url_list) == len(name_list)
for i, u in enumerate(url_list):
M3u8Download(u,
name_list[i] if sta else f"{name_list[0]}{i + 1:02}",
max_workers=64,
num_retries=10,
# base64_key='5N12sDHDVcx1Hqnagn4NJg=='
)也可以选择别人的项目进行下载
这样很快就能将每个网页能看的视频下载下来,省去挂机录制网课的时间了
抓包过程:
打开wireshark软件,在以太网上右键,点击start capture开始抓包
在开始抓包后我们立即播放一个课程,当课程画面出现2-3秒后停止抓包
抓取到的数据包过多,有许多都是我们不需要的,所以我们使用过滤器,筛选出我们需要的数据包在过滤器中输入http并且回车显示出所有的http的数据包
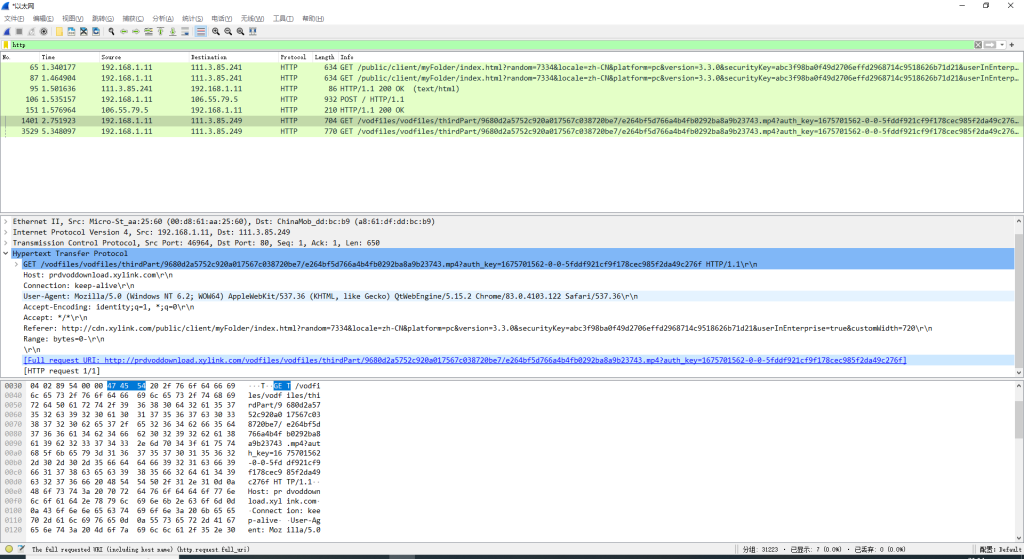
这时便获取到了软件课程的视频源。
